
Table of Links
2. Background
2.1 Effective Tutoring Practice
2.2 Feedback for Tutor Training
2.3 Sequence Labeling for Feedback Generation
2.4 Large Language Models in Education
3. Method
3.1 Dataset and 3.2 Sequence Labeling
3.3 GPT Facilitated Sequence Labeling
4. Results
6. Limitation and Future Works
APPENDIX
B. Input for Fine-Tunning GPT-3.5
C. Scatter Matric of the Correlation on the Outcome-based Praise
D. Detailed Results of Fine-Tuned GPT-3.5 Model's Performance
4.1 Results on RQ1
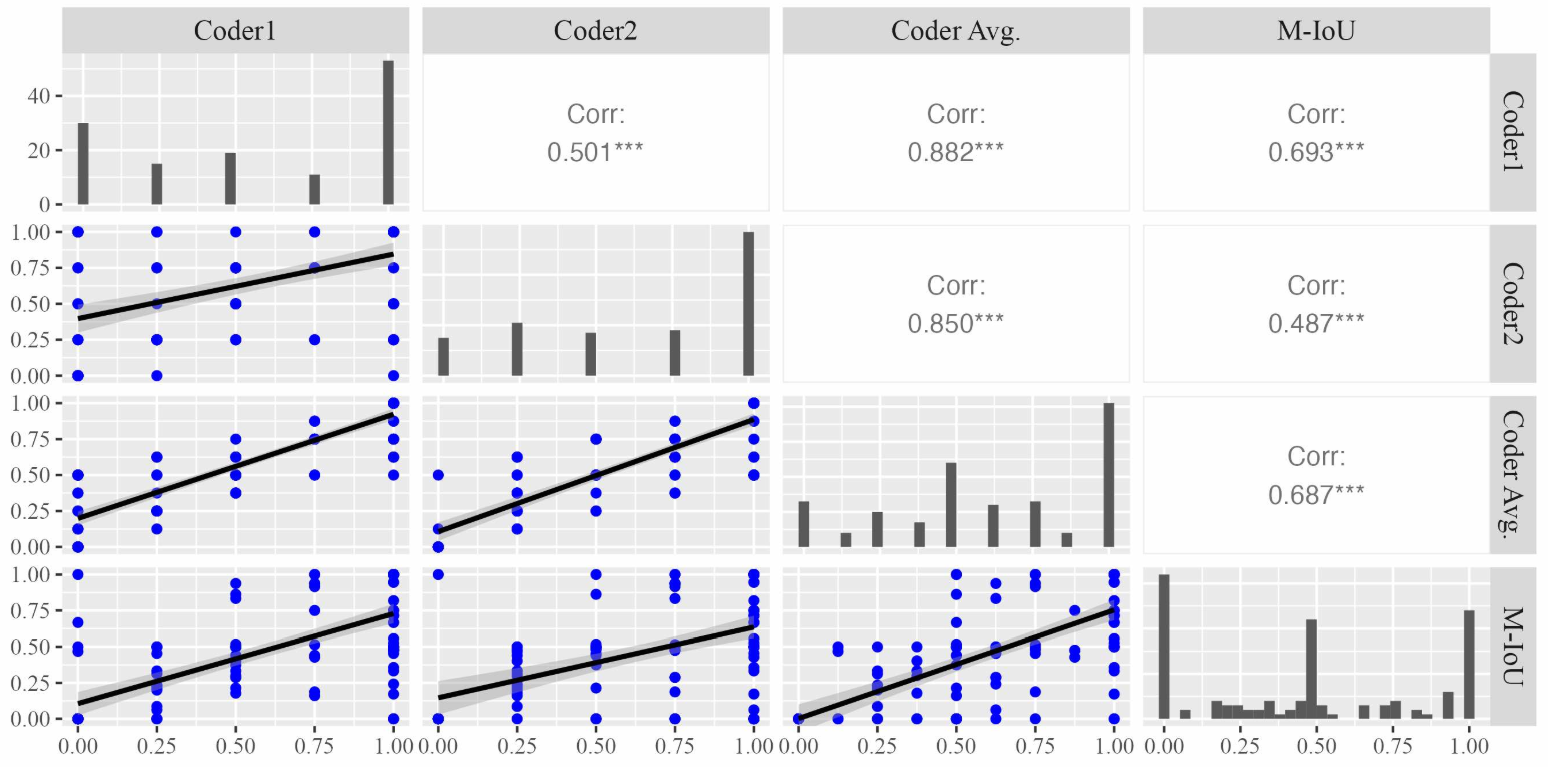
To answer RQ1, we aimed to evaluate the extent to which the models’ highlighted elements by prompting approach could adequately convey information necessary for identifying the type of praise being expressed. By doing so, we first conducted correlation analysis (as described in the Section 3.4.2) to validate the efficacy of Modified Intersection over Union (M-IoU) score. Due to the page limit,[2] we only present the results of correlation analysis for effort-based praise between the M-IoU scores and the coders’ ratings (shown in Figure 3). The findings revealed a significant positive correlation (p < 0.01) between the M-IoU scores and the ratings from both individual coders (Coder 1 and Coder 2) as well as the averaged scores of the coders (Coder AVG.) for the identification of effort-based praise. This significant correlation underscores the reliability and effectiveness of our proposed M-IoU metric in evaluating the quality of highlighted components from GPT models.
Then, we examined the quality of highlighted elements by prompting GPT-3.5 and GPT-4. In Table 4, we presented the descriptive statistics of the scores rated by two human coders and measured by M-IoU scores. Since the M-IoU score ranging from 0 to 1, to facilitate a direct comparison between human scores and M-IoU scores, we normalized the human coders’ rating scores (originally on a scale from 1 to 5) to the same 0 to 1 range. It is important to note that the calculation of M-IoU scores was based on the overlap of highlighted text between the GPT models and expert annotations; consequently, assigning an M-IoU score for expert annotation was not applicable and is thus indicated as N/A in Table 4. The results in Table 4 revealed that the highlighted text for outcome-based praise consistently received higher human rating scores and M-IoU scores than that for effort-based praise across both GPT models. This finding aligns with our intuition, considering that outcome-based praise, characterized by expressions such as “Good job” and “Well done,” tends to be more structured and straightforward to identify than the more nuanced effort-based praise. Interestingly, the difference in M-IoU scores between GPT3.5 and GPT-4 for both types of praise was marginal, despite the reputed superiority of the GPT-4 model in numerous educational tasks.
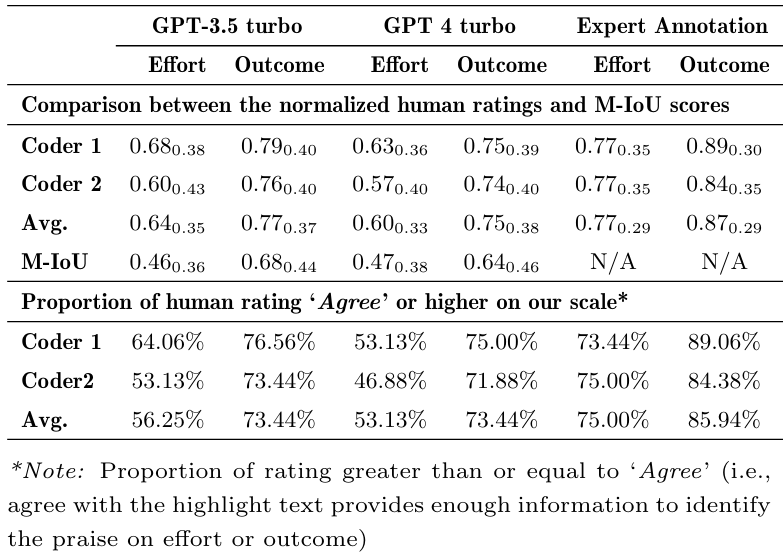
We further investigated the proportion of highlights that achieved a rating of 4 or above (corresponding to ‘Agree’ or higher on our scale), termed here as ‘satisfied highlighted text’. The proportion serves as an indicator of the highlights’ utility in facilitating the identification of the accurate type of praise. In Table 4, our analysis disclosed that over 50% of the effort-based praise highlights generated by prompting the GPT-3.5 model were deemed effective by the coders in identifying effort-based praise, whereas for outcome-based praise, the proportion exceeded 70%. Interestingly, the satisfaction proportion for GPT-3.5’s highlights surpassed those of GPT-4, suggesting a nuanced difference in their performance. Moreover, expert annotations were observed to yield the highest satisfaction rates, with over 70% for effort-based praise and 80% for outcome-based praise highlights considered satisfactory by the coders. The coders’ ratings for expert-annotated text were generally higher, reflecting the expert annotations’ authenticity and precision in capturing the essential elements of praise, which indicates the potential limitations of relying solely on Cohen’s Kappa for evaluating agreement in sequence labeling tasks. The coders’ perceptions affirm the significance of the highlighted texts’ quality over mere statistical agreement, indicating that expert annotations, despite a lower Cohen’s Kappa, effectively convey the essential attributes of praise within the tutor responses.
This paper is available on arxiv under CC BY 4.0 DEED license.
[2] The correlation analysis for outcome-based praise can be found in the Appendix C.
Authors:
(1) Jionghao Lin, Carnegie Mellon University ([email protected]);
(2) Eason Chen, Carnegie Mellon University ([email protected]);
(3) Zeifei Han, University of Toronto ([email protected]);
(4) Ashish Gurung, Carnegie Mellon University ([email protected]);
(5) Danielle R. Thomas, Carnegie Mellon University ([email protected]);
(6) Wei Tan, Monash University ([email protected]);
(7) Ngoc Dang Nguyen, Monash University ([email protected]);
(8) Kenneth R. Koedinger, Carnegie Mellon University ([email protected]).